|
|
|
CAPÍTULO 7: ANÁLISIS REGIONAL |
|
"En la mayoría de los sistemas naturales,
el drenaje de las tierras altas llega a los ríos y luego al océano.
La eliminación en el océano es la forma que tiene
la Naturaleza de sacar las sales disueltas del paisaje".
Jan van Schilfgaarde (1990) |
|
Este capítulo se divide en tres secciones. La Sección 7.1 describe las distribuciones de probabilidad conjuntas, incluyendo las distribuciones marginales y de probabilidad condicional. La Sección 7.2 describen las técnicas de análisis de regresión. La Sección 7.3 presenta las técnicas para el análisis regional de las características de las inundaciones y las precipitaciones. |
7.1 PROBABILIDAD CONJUNTA
|
|
En la ingeniería hidrológica, el análisis regional abarca el estudio de los
fenómenos hidrológicos con el objetivo de desarrollar relaciones matemáticas a
ser utilizadas en un contexto regional.
Distribuciones de Propabilidad Conjunta
Las distribuciones de probabilidades que poseen una variable aleatoria (X) se trataron en el Capítulo 6. Estos se llaman distribuciones univariables. Las distribuciones de probabilidades con dos variables aleatorias, X y Y, se llaman distribuciones bivariadas o distribuciones conjuntas. Una distribución conjunta expresa en términos matemáticos la probabilidad de ocurrencia de un resultado que consiste en un par de valores X e Y. En la notación estadística, P(X = xi, Y = yj) es la probabilidad P que las variables aleatorias X y Y tendrán los resultados xi y yj simultáneamente. Una notación más corta es P(xi, yj).
-------------------------------------
STOP HERE 230922 17:35
-------------------------------------
Para xi (1, 2, ..., n) y yj (1, 2, ..., m), la suma de las probabilidades de todos los resultados posibles es igual a la unidad:
|
n m Σ Σ P(xi, yj) = 1 i = 1 j = 1 | (7-1) |
Un ejemplo clásico de probabilidad conjunta es el de los resultados de lanzar dos dados, por ejemplo A y B. Intuitivamente, la probabilidad de obtener un 1 para A y 1 para B es P(A = 1, B = 1) = 1/36; véase la Fig. 7-1. Hay un total de 6 × 6 = 36 resultados posibles, y cada uno de ellos tiene la misma probabilidad: 1/36 (suponiendo, por supuesto, que los dados no están cargados). Esta distribución se conoce como la distribución uniforme bivariada, ya que cada resultado tiene una probabilidad de ocurrencia uniforme e igual. Se confirma que la suma de las probabilidades de todos los resultados posibles es igual a 1.
Figura 7-1 Probabilidad conjunta: El resultado de dos dados. |

Las probabilidades cumulativas conjuntas se definen de una manera similar como las probabilidades univariadas:
|
k l F(xk, yl) = Σ Σ P(xi, yj) i = 1 j = 1 | (7-2) |
en la cual F(xk,
y
Distribución Marginal de Probabilidades
Las distribuciones marginales de probabilidades
se obtienen mediante la suma de P(xi, yj) sobre todos los valores de una de las variables, por ejemplo, X.
La distribución (marginal) resultante es la distribución de probabilidad de la otra variable,
en este caso Y sin tener en cuenta X.
|
m P(xi) = Σ P(xi, yj) j = 1 | (7-3) |
Del mismo modo, la distribución marginal de Y es:
|
n P(yj) = Σ P(xi, yj) i = 1 | (7-4) |
El ejemplo de los dos dados A y B se puede utilizar para ilustrar el concepto de probabilidad marginal. Intuitivamente, la probabilidad de A es igual a 1, sin importar el valor de B, es 6 × (1/36) = 1/6. Del mismo modo, la probabilidad de B es igual a 4, independientemente del valor de A, también es 1/6. Observe que las probabilidades conjuntas (1/36) de cada uno de los 6 posibles resultados se han resumido con el fin de calcular la probabilidad marginal.
Las distribuciones de probabilidades marginales cumulativas se obtienen mediante la combinación de los conceptos de distribuciones marginales y cumulativas. En la notación estadística, la distribución de probabilidad marginal cumulativa de X es:
|
k m F(xk) = Σ Σ P(xi, yj) i = 1 j = 1 | (7-5) |
Del mismo modo, la distribución marginal de Y es:
|
n l F(yl) = Σ Σ P(xi, yj) i = 1 j = 1 | (7-6) |
El ejemplo de los dos dados A y B se utiliza nuevamente para ilustrar el concepto de probabilidad marginal cumulativa. La probabilidad de A ≤ 2, independientemente del valor de B, es: 2 × 6 × (1/36) = 1/3. Del mismo modo, la probabilidad de B ≤ 5, sin tener en cuenta el valor de A, es: 5 × 6 × (1/36) = 5/6. Para el cálculo de las probabilidades marginales cumulativas los conceptos de distribuciones marginales y cumulativas se han combinado.
-------------------------------------
STOP HERE 230926 12:00
-------------------------------------
La probabilidad condicional
El concepto de probabilidad condicional es útil en el análisis de regresión y otras aplicaciones hidrológicas. La probabilidad condicional es el cociente de las probabilidades conjuntas y marginales. En la notación estadística:
|
P(x,y) P(x |y) = ________ P(y) | (7-7) |
en la cual P(x | y) es la probabilidad condicional de x, dado y. Del mismo modo, dada la probabilidad condicional de y, dado x, es:
|
P(x,y) P(y |x) = ________ P(x) | (7-8) |
A partir de las ecuaciones 7-7 y 7-8, se deduce que la probabilidad conjunta es el producto de las probabilidades condicionales y marginales.
Las distribuciones de probabilidad conjunta se pueden expresar como funciones continuas.
En este caso se les llama funciones de densidad conjunta, con la notación f(x,y).
Para la función de densidad condicional, la notación es
Al igual que con las distribuciones univariadas, los momentos proporcionan descripciones de las propiedades de las distribuciones de conjuntos. Para las funciones continuas, el momento conjunto de orden r y s sobre el origen (indicado con ') se define de la siguiente manera:
|
∞ ∞ μ'r,s = ∫ ∫ x ry s f (x,y ) dy dx -∞ -∞ | (7-9) |
Con r = 1 y s = 0, la Ec. 7-9 se reduce a la media de x :
|
∞ ∞ μ'1,0 = ∫ x [ ∫ x ry s f (x,y ) dy ] dx -∞ -∞ | (7-10) |
con la expresión entre paréntesis siendo el PDF marginal de x o f(x). Por lo tanto, la expresión para la media de x es:
|
∞ μ'1,0 = μx = ∫ x f (x ) dx -∞ | (7-11) |
Ecuaciones similares son válidas para y.
Los segundos momentos se escriben normalmente sobre la media:
|
∞ ∞ μ'r,s = ∫ ∫ ( x - μx )r ( y - μy )s f (x,y ) dy dx -∞ -∞ | (7-12) |
Para r = 2 y s = 0, la
|
∞ ∞ σx,y = ∫ ∫ ( x - μx ) ( y - μy ) f (x, y ) dy dx -∞ -∞ | (7-13) |
en la cual σx,y es la covarianza.
El coeficiente de correlación es un valor adimensional que relaciona la covarianza σx,y y las desviaciones estándar σx y σy :
|
σx,y ρx,y = _________ σx σy | (7-14) |
en la cual ρx,y es el coeficiente de correlación basado en los datos de población. El coeficiente de correlación de la muestra es:
|
sx,y rx,y = ________ sx sy | (7-15) |
El cálculo del coeficiente de correlación de la muestra rx,y,
incluyendo la covarianza de la muestra sx,y, se ilustra con el Ejemplo 7-1.
El coeficiente de correlación es una medida de la dependencia lineal entre x y y.
El coeficiente varía entre -1 a + 1.
Un valor de ρ (o r) cerca o igual a 1 indica una fuerte dependencia lineal entre las variables,
con grandes valores de x asociados con grandes valores de y,
y pequeños valores de x con pequeños valores de y.
Un valor de ρ (o r) cerca o igual a -1 indica una correlación tal que grandes valores de x se asocian con valores pequeños de y y vice versa.
Un valor de ρ = 0
-------------------------------------
STOP HERE 230926 16:40
-------------------------------------
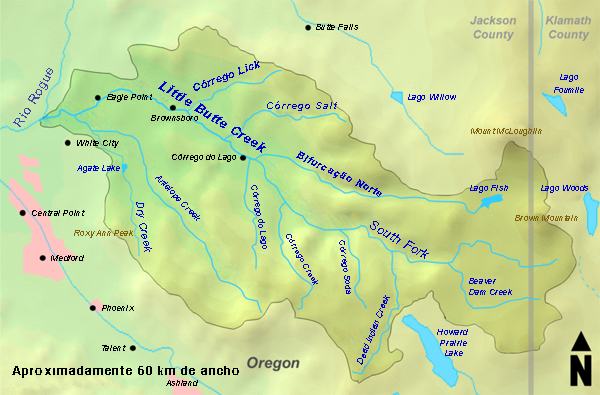
Ejemplo 7-1.
Los flujos mensuales de los afluentes de North Fork y South Fork de cierta corriente (véase,
por ejemplo, la Fig. 7-2) tienen la siguiente distribución de probabilidad conjunta
f(x, y) (expresado como valor medio en cada clase) (Nótese que 1 hm3 = 1 millón de metros cúbicos):
Calcular las distribuciones marginales, medias, varianzas, desviaciones estándar,
covarianza y coeficiente de correlación para esta distribución conjunta.
La distribución marginal de North Fork, f(x), se obtiene sumando las probabilidades conjuntas a través de y.
Por consiguiente:
Del mismo modo, la distribución marginal de South Fork, f(y), se obtiene
sumando las probabilidades conjuntas a través de x:
Las medias son los primeros momentos de las distribuciones marginales con respecto al origen:
Las varianzas son los segundos momentos de las distribuciones marginales con respecto a las medias:
sx2 = Σ ( x - x̄ )2 f (x) Por consiguiente:
sx = 95.26 hm3
Asimismo, para y:
sy = 97.42 hm3
La covarianza es el segundo momento de la distribución conjunta:
El coeficiente de correlación es rx,y = sx,y / (sx sy) = 7785 / (95.26 × 97.42) = 0.839.
CÁLCULO EN LÍNEA. Utilizando
ONLINE TWOD CORRELATION,
la respuesta es: coeficiente de correlación rx,y = 0.839, confirmando
el cálculo manual.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Figura 7-2 North Fork y South Fork, Little Butte Creek, Oregon.
Distribución normal bivariada
Entre las distribuciones de probabilidad conjunta, la distribución normal bivariada es importante en la hidrología porque es el fundamento de la teoría de la regresión. La distribución de probabilidad normal bivariada es [12]:
| f (x , y) = K e M | (7-16) |
en la cual x y y son las variables aleatorias, y K y M son coeficiente y exponente, respectivamente, que se define como sigue:
|
1 K = _________________________ 2 π σx σy (1 - ρ2)1/2 | (7-17) |
|
1 M = - ___________ [ A ] 2 (1 - ρ2) | (7-18a) |
en la cual:
|
x - μx x - μx y - μy y - μy A = ( _________ )2 - 2 ρ ( _________ ) ( _________ ) + ( _________ )2 σx σx σy σy | (7-18b) |
La distribución tiene cinco parámetros: los medios μx y μy, las desviaciones estándar σx y σ y, y el coeficiente de correlación ρ.
Después de la Ec. 7-8, la distribución condicional se obtiene dividiendo el bivariante normal (Ec. 7-16) por el univariado normal (Ec. 6-7), para producir
|
f
(x, y) K = _________ = K' eM' f (x) | (7-19) |
en el que K' y M' son coeficiente y exponente, respectivamente, que se define de la siguiente manera:
|
1 K' = _____________________ σy [2 π (1 - ρ2)]1/2 | (7-20) |
|
1
σy M' = - ________________ [ (y - μy) - ρ ______ (x - μx) ]2 2 σy2 (1 - ρ2) σx | (7-21) |
Por inspección de las Ecs. 7-20 y 7-21, y la comparación con la Ec. 6-7, se concluye que la distribución condicional también es normal, con media y la varianza:
|
σy μy|x = μy - ρ _____ (x - μx) σx | (7-22) |
| σe2 = σy2 (1 - ρ2) | (7-23) |
Las Ecuaciones 7-22 y 7-23 son útiles en el análisis de regresión. La Ecuación 7-22 expresa la dependencia lineal entre el x e y. La pendiente de la línea de regresión es [ρ σ y/σx]. Del mismo modo, ρ es la fracción de la varianza inicial explicado o eliminado por la regresión. En otras palabras, la varianza de la distribución condicional es menor que o igual a la varianza de y sin tener en cuenta x, y depende del valor del coeficiente de correlación ρ. Para ρ = 1, toda la varianza se remueve, y el error de la ecuación de predicción (es decir, el error de la regresión) se reduce a cero. Para ρ = 0, no se elimina nada de la varianza original, y σe se mantiene igual a σy.
-------------------------------------
STOP HERE 230927 14:10
-------------------------------------
7.2 ANÁLISIS DE REGRESIÓN
|
|
Una herramienta fundamental de análisis regional es la ecuación que relaciona dos o más variables hidrológicas. La variable para la que se dan los valores se llama variable predictora. La variable para la que se deben estimar los valores se llama variable de criterio [7]. La ecuación que relaciona la variable criterio a una o más variables predictoras se llama la ecuación de predicción.
El objetivo del análisis de regresión es evaluar los parámetros de la ecuación de predicción que relaciona la variable criterio a una o más variables predictivas. Las variables predictivas son aquellas cuya variación se cree que causa o que esté de acuerdo con la variación en la variable criterio.
La correlación proporciona una medida de la bondad de ajuste de la regresión. Por lo tanto, mientras que la regresión proporciona los parámetros de la ecuación de predicción, la correlación describe su calidad. La distinción entre correlación y regresión es necesaria porque las variables predictivas y de criterio no se pueden intercambiar a menos que el coeficiente de correlación sea igual a 1. Expresado en otros términos, si una variable criterio Y es regresada en una variable predictor X, los parámetros de regresión no pueden ser usados para expresar X como una función de Y, a menos que el coeficiente de correlación sea 1. En el modelo hidrológico, el análisis de regresión es útil en la calibración del modelo; la correlación es útil en la formulación y verificación del modelo.
El principio de los mínimos cuadrados se utiliza en el análisis de regresión como un medio de obtener las mejores estimaciones de los parámetros de la ecuación de predicción. El principio se basa en la minimización de la suma de los cuadrados de las diferencias entre los valores observados y los predichos. El procedimiento se puede utilizar para la regresión de una variable criterio a una o más variables predictivas.
-------------------------------------
STOP HERE 230927 16:00
-------------------------------------
Regresión de una Variable Predictiva
Asumir una variable predictiva x, una variable criterio de y, y un conjunto de n observaciones pareadas de x y y. En el caso lineal más simple, la línea que se va a buscar tiene la siguiente forma:
| y' = α + βx | (7-24) |
en la cual y' es una estimación de y, y α y β son parámetros que se determinan por regresión.
En el procedimiento de mínimos cuadrados, los valores de la intercepción α y la pendiente β se buscan tal que y' es la mejor estimación de y. Para este propósito, la suma de los cuadrados de las diferencias entre y y y' se minimizan como sigue:
| Σ ( y - y' )2 = Σ [ y - ( α + βx ) ] 2 | (7-25) |
en la cual el símbolo Σ indica la suma de todos los valores de i = 1 hasta i = n.
Haciendo las derivadas parciales iguales a cero:
|
∂ ____ { Σ [ y - ( α + βx ) ] 2 } = 0 ∂α | (7-26) |
|
∂ ____ { Σ [ y - ( α + βx ) ] 2 } = 0 ∂β | (7-27) |
Esto lleva a las ecuaciones normales:
| Σ y - nα - β Σ x = 0 | (7-28) |
| Σ xy - α Σ x - β Σ x2 = 0 | (7-29) |
Resolviendo las ecuaciones 7-28 y 7-29 simultáneamente da:
|
Σ xy - ( Σ x Σ y ) / n β = ________________________ Σ x2 - ( Σ x )2 / n | (7-30) |
|
Σ y
- β Σ x α = __________________ n | (7-31) |
Dado que la pendiente de la línea de regresión es: β = ρ σy /σx, la estimación de los datos de la muestra es:
|
sx r = β ____ sy | (7-32) |
El error estándar de estimación de la correlación es la raíz cuadrada de la varianza de la distribución condicional:
|
1 se = [ ______ Σ (y - y' )2 ] 1/2 n - 2 | (7-33) |
en la cual n - 2 es el número de grados de libertad, es decir, el tamaño de la muestra menos el número de incógnitas.
Alternativamente, el error típico de estimación puede estimarse a partir de la varianza de la distribución condicional, Eq. 7-23. Para los cálculos basados en datos de la muestra, el error estándar de estimación es:
|
n - 1 se = sy [ ______ (1 - r 2) ] 1/2 n - 2 | (7-34) |
Ecuaciones no lineales.
Las Ecuaciones 7-30 y 7-31 también se pueden utilizar para adaptarse a funciones de potencia del tipo
-------------------------------------
Ejemplo 7-2.
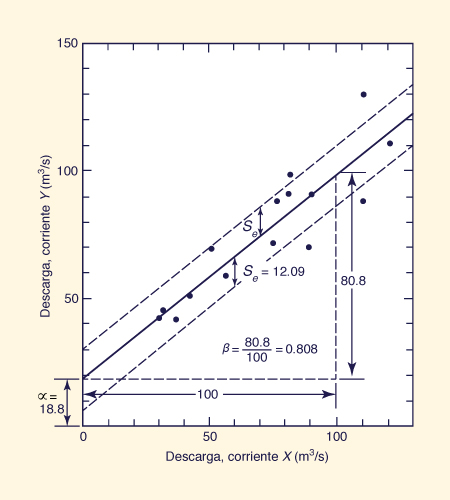
Encuentre la ecuación de regresión que une los flujos bajos (series mínimos anuales) de los arroyos de X y Y mostrado en las Cols. 2 y 3 de la Tabla 7-1. Calcular
los parámetros de regresión lineal α y β, el coeficiente de correlación, y el error estándar de la estimación.
Sumando los valores de las Columnas 2 y 3, y dividiendo por n = 15, se obtienen las medias:
x̄ = 72 m3/s y ȳ = 77 m3/s.
Las columnas 4 y 5 muestran el cuadrado de las desviaciones de las medias. Sumando las
columnas 4 y 5, dividiendo la suma por (n - 1) = 14, y tomando las raíces cuadradas,
se obtienen
las desviaciones estándar sx = 29.568 m3/s y s y = 26.589 m3/s.
La Columna 6 muestra los valores x2 y la Col. 7, los valores xy.
La suma de estos valores es: Σ x2 = 90,000 y Σ xy = 93,056.
Utilizando la Ec. 7-30: β = [93,056 - (1,080 × 1,155)/ 15 ] / [ 90,000 - (1,080 × 1,080)/ 15] = 0.80849.
Utilizando la Ec. 7-31: α = [1155 - (0.8085 × 1080)] / 15 = 18.7882.
Utilizando la Ec. 7-32, el coeficiente de
correlación es: r = 0.80849 × 29.568 / 26.589 = 0.899.
Usando la Ec. 7-34, el error estándar
de estimación es: se = 26.589 × [(14/13) (1 - 0.8992)] 1/2 =
Los datos y la línea de regresión se representan en la Fig. 7-3.
CALCULO EN LÍNEA. Utilizando
ONLINEREGRESSION11,
la respuesta
es: α = 18,7882;
Figure 7-3
Regresión (una variable predictiva): Ejemplo 7-2.
-------------------------------------
Regresión múltiple
La extensión de la técnica de mínimos cuadrados a más de una
variable predictora se conoce como regresión múltiple.
En el caso de dos variables predictoras, x1 y x2, con
la variable criterio y y un conjunto de n observaciones de y,
x1 y x2, la línea a ser ajustada es:
en el cual x1 y x2 son los valores medidos y y' es una estimación de y.
Al igual que con el caso de dos variables, los valores del intercepto α
y las pendientes β1 y β2 se buscan de tal manera que
y' es la mejor estimación de
y. Para este propósito, se minimizan
la suma de los cuadrados de las diferencias entre y e y'.
Colocando las derivadas parciales con respecto a α, β 1 y β2 igual a cero
conduce a las ecuaciones normales:
Resolviendo las Ecuaciones 7-37 a 7-39 simultáneamente:
Como en el caso de la regresión de una variable predictora, el error estándar de
estimación de la correlación es la raíz cuadrada de la varianza de la
distribución condicional:
en el cual n - 3 es el número de grados de libertad.
Alternativamente, el error estándar de estimación puede estimarse a partir de la varianza de
la distribución condicional. Para los cálculos basados en datos de la muestra, el error
estándar de estimación es:
en el cual R = coeficiente de regresión múltiple, o coeficiente de
determinación múltiple, calculado de la siguiente manera [8]:
en el cual SSE = suma de cuadrados, definido como
y SSTO = suma total de cuadrados, definido como
Regresión Múltiple no Lineal
Las ecuaciones 7-40 a 7-42 también se puede utilizar para adaptarse a ecuaciones del tipo:
En primer lugar, esta ecuación se linealiza mediante la adopción de los logaritmos:
Con u = log x1 v = logx2 y w = logy,
esta ecuación es: w = loga + bu + cv.
Las variables u, v y w se utilizan en las ecuaciones 7-40 a 7-42 en lugar de x1, x2 y y, respectivamente.
Entonces α = log a, β1 = b1, β2 = b2, y la ecuación de regresión es:
El análisis de regresión múltiple en la que
participan más de dos variables predictoras
se basa en el mismo principio de mínimos cuadrados como en los casos muestrados aquí.
Los programas de software institucional están disponibles para llevar a cabo la gran cantidad de
cálculos necesarios.
------------------------------------- 7.3 ANÁLISIS REGIONAL
Flujo Pico Basado en el Área de la Cuenca
La primera aproximación a la regionalización de las propiedades hidrológicas
era suponer que el flujo pico está relacionado con el
área de la cuenca, y realizar una regresión para determinar los parámetros.
La ecuación es de la siguiente forma:
en la cual Qp = flujo pico; A = área de la cuenca; y c y m son parámetros de regresión.
En la Naturaleza, a medida que aumenta el área de la cuenca, la intensidad de precipitación
media espacialmente distribuida disminuye,
y consecuentemente el flujo pico aumenta tan rápido como
el área de la cuenca.
Por lo tanto, el exponente m en la Ec. 7-51 siempre menor que 1, por lo general en el rango de 0.4
a 0.9 [5, 10].
Ejemplos prácticos del uso de este método se dan en la Sección 14.6.
Otras fórmulas relacionadas de flujo pico en función del
área de cuenca son las siguientes:
en las cuales a, b, c, d, m y n son parámetros determinados a partir de un
análisis estadístico de los datos medidos y son aplicables a nivel regional,
es decir, para las cuencas vecinas con similar
fisiografía, vegetación, y uso de la tierra.
Las curvas Creager (Fig. 2-73) son un ejemplo de la Ec. 7-52 [3]. La Ecuación 7-53
ha sido utilizada en estudios de inundaciones regionales en el Suroeste [2, 6, 9],
mientras que la Ec. 7-54 parece ser típica de
la práctica europea [5].
En principio, ninguna de estas ecuaciones representa explícitamente la frecuencia de
inundación, estando limitada a proporcionar un flujo pico.
El efecto de la frecuencia de inundaciones, sin embargo, puede ser explicada
variando los parámetros (Sección 14.6).
Método de Índice-Inundación
El método de índice-inundación se utiliza para determinar la magnitud y
la frecuencia de los caudales máximos para cuencas de cualquier tamaño,
ya sea aforadas o no aforadas, situadas dentro de una región hidrológicamente
homogénea, es decir, una región con características hidrológicas similares [1, 4].
La aplicación del método de
índice de inundación consiste en desarrollar dos curvas.
La primera curva representa la inundación anual media (es decir, la correspondiente a la
frecuencia de 2.33-y) versus el área de cuenca.
La segunda curva muestra la relación de flujo pico versus frecuencia.
El procedimiento consta de los siguientes pasos:
Medición del área de la cuenca,
Uso de la primera curva para obtener la inundación media anual,
Uso de la segunda curva para obtener las relaciones de flujo pico para las
frecuencias seleccionadas,
Cálculo de los flujos máximos para cada frecuencia, y
Gráficos de los flujos pico versus las frecuencias.
-------------------------------------
Avenida Media Anual
La magnitud de la avenida media anual es una función de varios factores fisiográficos
y meteorológicos. Los factores fisiográficos que pueden influir en la avenida media anual son los siguientes:
Área de drenaje.
Almacenamiento en el canal.
Almacenamiento artificial o natural en lagos y estanques.
Pendiente de la cuenca.
Pendiente del terreno.
Densidad y patron de las corrientes.
Elevación media del terreno.
Forma de la cuenca.
Posición orográfica.
Geología subyacente.
Cobertura vegetal del suelo, y
Patrones de vegetación y uso de la tierra.
Los factores meteorológicos incluyen:
Características climáticas regionales.
Intensidades de lluvia.
Dirección de la tormenta, patrón y volumen.
Efecto de la nieve derretida.
De los factores mencionados, el área de drenaje es la más importante y la más
fácil de conseguir.
Curva Regional de Frecuencia.
El procedimiento para desarrollar una curva de frecuencia regional mediante el método del
índice de inundación consta de los siguientes pasos:
Reunir los registros (excedencia anual o series máximos anuales) de varias estaciones
(por lo general de 10 a 15), cada uno con más de 5 años de registro.
Seleccionar una base de tiempo común a todas las estaciones (período de
base común de análisis) con el fin de eliminar el efecto de la variabilidad con el tiempo.
Para cada estación i, clasificar los registros en orden descendente y calcular
los períodos de retorno utilizando una fórmula de posición gráfica como la de Weibull (Ec. 6.26).
Para cada estación i, graficar los flujos anuales frente a periodos de retorno
en el papel de probabilidad de valores extremos y ajustar una línea visual para
determinar la curva de frecuencia.
Para cada i th estación i, determinar la avenida media anual, es decir,
el flujo pico correspondiente a la frecuencia de 2.33-y.
Elija varias frecuencias, y para cada i th estación i
y frecuencia j calcular
la relación de flujo máximo, es decir,
la relación de flujo máximo para la frecuencia j a la avenida media anual.
Para cada frecuencia j,
determinar el valor de la mediana de los relaciones de flujo máximo
para todas las estaciones, es decir, la relación de flujo máximo mediana.
Gtraficar la relación de la mediana del flujo máximo frente
a frecuencias en el papel de probabilidad de valores extremos y graficar una línea
de mejor ajuste para obtener una curva de frecuencia de inundación regional
de los datos correspondientes.
Prueba de Homogeneidad Hidrológica
El método del índice de inundación
incluye una prueba de homogeneidad hidrológica regional.
Cualquier estación que no pase esta prueba debe ser excluida del conjunto.
El procedimiento de ensayo
consta de los siguientes pasos [4]:
Para cada estación i, utilizar su curva de frecuencia para determinar las inundaciones
correspodientes a
2.33 años y 10 años.
Para cada estación i, calcular la relación de flujo máximo de 10 ańos,
es decir,
la relación de la inundación de 10 años a la inundación de 2.33 años.
Calcular el promedio de las proporciones de flujo máximo de 10 años para todas las estaciones.
Para cada estación i, multiplique la inundación de 2.33 años por
el promedio de la relación de flujo máximo de 10 años
para obtener un flujo máximo de 10 años ajustado.
Para cada estación i, utilice su curva de frecuencia para determinar el período de retorno
de Ti para el flujo máximo de 10 años ajustado.
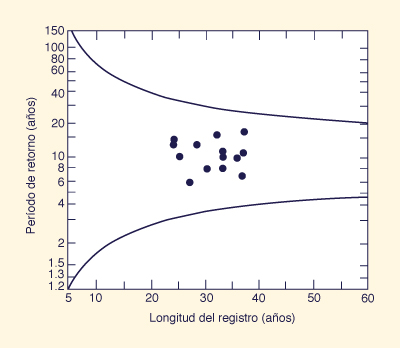
Para cada estación i, graficar el período de retorno Ti frente
a la longitud de registro n, en los años, en la Fig. 7-4.
Los puntos situados dentro de los límites de confianza (líneas continuas) se consideran que son
hidrológicamente homogéneos.
Los puntos que se encuentran fuera de las líneas sólidas no deben utilizarse en el cálculo de la relación de flujo pico mediano (paso 7 del método del índice de inundaciones).
Figure 7-4 Prueba de homogeneidad para el método del indice de inundación [4].
-------------------------------------
Limitations of the Index-Flood Method.
Limitaciones del Método Índice-Inundación.
Benson [1] has noted the following limitations of the index-flood method:
Benson [1] ha tomado nota de las siguientes limitaciones del método índice-inundación:
The mean annual flood for stations with short periods of record may not be typical, which means that the peak flow ratios of different return periods may vary widely among stations.
La inundación media anual para estaciones con períodos cortos de registro
no pueden ser típicos, lo que significa que las relaciones de flujo máximo de los diferentes periodos de retorno pueden variar ampliamente entre las estaciones.
The homogeneity test is used to determine whether the differences in the frequency curves are greater than those that could be attributed to chance alone. The index-flood test uses the 10-y flow ratio because of the lack of sufficient data to define the frequency curve adequately at longer return periods.
Studies have shown that although homogeneity may be assumed on the basis of the 10-y peak flow ratio,
the individual frequency curves may show wide and sometimes systematic differences at longer return periods.
La prueba de homogeneidad se utiliza para determinar si las diferencias en las curvas de frecuencia
son mayores que los que podría atribuirse a la casualidad.
La prueba de índice-inundación utiliza la relación de flujo de 10-y debido a la falta de datos suficientes para definir la curva de frecuencia adecuada a largo de períodos de retorno.
Los estudios han demostrado que a pesar de la homogeneidad puede suponerse sobre la base de la
relación de flujo máximo de 10-y, las curvas de frecuencia individuales pueden mostrar
amplias y a veces diferencias sistemáticas en períodos de retorno más largos.
The method combines frequency curves for all catchment sizes, excluding only the largest.
At the 10-y peak flow ratio level, the effect of catchment size is small and can be neglected. Studies have shown that the peak flow ratios tend to vary inversely with catchment size. In general, the larger the catchment,
the flatter the frequency curve and the lower the peak flow ratios. The effect of catchment size is particularly marked for floods of long return period.
El método combina curvas de frecuencia para todos los tamaños de captación,
excluyendo sólo el más grande.
A nivel de relación de flujo máximo de 10-y, el efecto del tamaño de captación
es pequeña y se puede despreciar. Los estudios han demostrado que las relaciones de flujo máximo
tienden a variar inversamente con el tamaño de captación. En general, cuanto mayor sea
la captación, más plana la curva de frecuencia y las relaciones de flujo máximo inferior.
El efecto del tamaño de captación es particularmente marcado por las inundaciones de
periodo de retorno de largo.
Example 7-3.
Use the Qi/Q2.33 data for the five stations shown in Table 7-2 to develop a regional flood frequency curve by the index-flood method.
Assuming Q2.33 = 2.5A0.6, in which Q2.33 is in cubic meters per second and catchment area A is in square kilometers, calculate the 50-y flood for a 150-km2 catchment based on the regionally developed curve.
Utilice los datos Qi/Q2.33 para las cinco estaciones que se muestran en la
Tabla 7-2 para desarrollar una curva de frecuencia de inundación regional mediante el método
del índice de las inundaciones.
Suponiendo Q2.33 = 2.5A0.6 , en el que Q2.33
está en metros cúbicos por segundo y el área de captación A
está en kilómetros cuadrados, calcular la inundación para 50-y de una cuenca de 150-km2 basada en la curva desarrollada regionalmente.
The median values are shown at the bottom of each column.
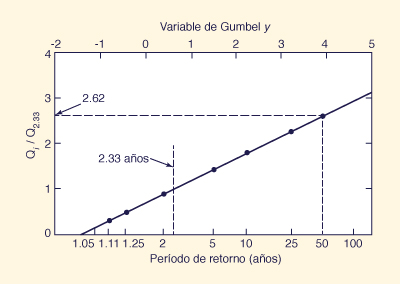
These values are plotted against the return period, as shown in Fig. 7-5.
The fitted line is the regional flood-frequency curve.
For a 150-km2 catchment, the mean annual flood is: 50.5 m3/s.
From Fig. 7-5, the peak flood ratio for the 50-y return period is 2.62.
Therefore, the 50-y flood for this catchment is 132 m3/s.
Los valores de la mediana se muestran en la parte inferior de cada columna.
Estos valores se grafican frente el período de retorno, como se muestra en la Fig. 7-5.
La línea ajustada es la curva de frecuencia de inundación regional.
Para una cuenca de 150-km2, la inundación media anual es de: 50.5 m3/s.
De la Fig. 7-5, la relación de flujo máximo para el periodo de retorno de 50-y es de 2.62.
Por lo tanto, la inundación de 50-y para esta cuenca es de 132 m3/s.
Figure 7-5 Index-flood method: Example 7-3. / Método Índice-Inundación: Ejemplo 7-3.
Las precipitaciones de Intensidad-Duración-Frecuencia
Curves showing the relationship between intensity, duration, and frequency of rainfall (IDF curves) are required for peak flow computations in small catchments (see rational method, Chapter 4).
These curves can be developed using either: (a) depth-duration-frequency data provided by the National Weather Service, or (b) regional or local rainfall intensity-duration data.
The latter procedure is illustrated by the following example.
Se requieren curvas que muestran la relación entre la intensidad, duración y frecuencia
de las precipitaciones (curvas IDF) para cálculos de flujo máximo requeridas
en pequeñas cuencas (véase el método racional, capítulo 4).
Estas curvas se pueden desarrollar utilizando ya sea: (a) los datos de profundidad-duración-frecuencia proporcionados por el Servicio Meteorológico Nacional, o (b) datos de precipitaciones regionales o locales de intensidad-duración. Este último procedimiento se ilustra mediante el siguiente ejemplo.
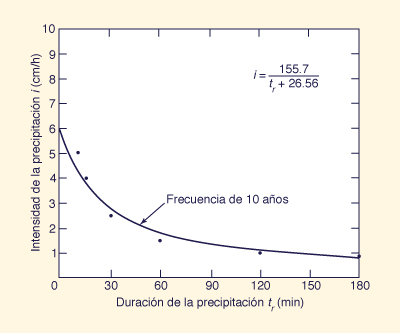
Example 7-4.
Determine the equation relating rainfall intensity and duration for the following 10-y frequency rainfall data.
Determinar la ecuación que relaciona la intensidad de precipitación y la duración
de los siguientes datos de precipitación de 10-y de frecuencia.
The data suggest that the relation is of hyperbolic type, with greater intensities associated with shorter durations.
Therefore, an equation of the type of Eq. 2-6 is applicable:
Los datos sugieren que la relación es de tipo hiperbólico, con mayor intensidad
asociado con duraciones más cortas. Por lo tanto, una ecuación del tipo de la Ec. 2-6 es aplicable:
in which a and b are constants to be determined by regression analysis.
This equation can be linearized in the following way:
en la que a and b son constantes a determinar por el análisis de regresión.
Esta ecuación se puede linealizar de la siguiente forma:
With y = 1/i, x = tr, α = b/a, and β = 1/a, the application of the regression formulas (Eqs. 7-30 and 7-31) to the data leads to: 1/i = 0.006422 tr, + 0.1706, in which α = 0.1706 and β = 0.006422.
Therefore: a = 155.7 and b = 26.56.
The regression equation is: i = 155.7 / (tr + 26.56).
The data and regression line are shown in Fig. 7-6.
Con y = 1/i, x = tr, α = b/a, y β = 1/a,
la aplicación de las fórmulas de regresión (Ecs. 7-30 y 7-31)
a los datos conduce a 1/i = 0.006422 tr, + 0.1706, en el que α = 0.1706 y β = 0.006422.
Por lo tanto: a = 155.7 y b = 26.56.
La ecuación de regresión es: i = 155.7 / (tr + 26.56).
Los datos y la línea de regresión se muestran en la Fig. 7-6.
ONLINE CALCULATION. Using
ONLINEREGRESSION15,
the answer
is: a = 155.702;
CALCULADORA EN LÍNEA. Usando
ONLINEREGRESSION15, la respuesta es: a = 155.702;
Figure 7-6 Ajuste de curvas de intensidad-duración-frecuencia: Ejemplo 7-4.
Ecuaciones de Estado para la Frecuencia de Inundación Regional
The U.S. Geological Survey has developed a comprehensive methodology for regional analysis of flood frequency [11].
Details of this method are given in Section 14.6.
El Servicio Geológico de Estados Unidos ha desarrollado una metodología completa para el
análisis regional de la frecuencia de inundaciones [11]. Los detalles de este método se dan
en la Sección 14.6.
PREGUNTAS
What is a joint probability? What is a marginal probability?
¿Qué es una probabilidad conjunta? ¿Qué es una probabilidad marginal?
What is a joint density function? Give an example.
¿Qué es una función de densidad conjunta? Dar un ejemplo.
What is a conditional probability? How is it used in regression analysis?
¿Qué es una probabilidad condicional? ¿Cómo se utiliza en el análisis de regresión?
Define covariance.
Definir la covarianza.
What is a correlation coefficient?
¿Qué es un coeficiente de correlación?
What is the difference between correlation and regression?
¿Cuál es la diferencia entre correlación y regresión?
Describe briefly the index-flood method for regional analysis of flood frequency.
Describir brevemente el método de índice-inundación para el análisis
regional de la frecuencia de inundaciones.
PROBLEMAS
Using ONLINE TWOD CORRELATION,
calculate the correlation coefficient of the following joint distribution of quarterly flows (expressed as mean values in each class) in streams A and B:
Usando ONLINE TWOD CORRELATION, calcular el coeficiente de
correlación de la siguiente distribución conjunta de los flujos trimestrales (expresado como valores medios en cada clase) en las
corrientes A y B:
Develop a spreadsheet to calculate the regression constants, correlation coefficient, and standard error of estimate of a series of paired flow values X and Y. Test your program using the data of Example 7-2 in the text.
Desarrollar una hoja de cálculo para calcular las constantes de regresión,
el coeficiente de correlación, y el error estándar de la estimación
de una serie de valores de flujo pareadas X e Y.
Probar su programa usando los datos del ejemplo 7-2 en el texto.
Using the spreadsheet developed in Problem 7-2, calculate the regression constants, correlation coefficient, and standard error of estimate for the following paired low-flow series (annual minima):
El uso de la hoja de cálculo desarrollado en el Problema 7-2, calcular las constantes de regresión,
el coeficiente de correlación y el error estándar de estimación para la siguiente serie de bajo flujo pareadas (mínimos anuales):
Verify with ONLINE REGRESSION11.
Verifique con ONLINE REGRESSION11.
Modify the spreadsheet developed in Problem 7-2 to calculate the regression constants to fit a power function of the following form (Eq. 7-51):
in which Qp = peak discharge; A = drainage area; c and m are coefficient and exponent, respectively.
Using the spreadsheet, fit a power function to the following data:
Modificar la hoja de cálculo desarrollada en el Problema 7-2 para el cálculo de las constantes
de regresión para adaptarse a una función de potencia de la siguiente forma (Ec. 7-51):
en el que Qp = descarga máxima; A = área de drenaje;
c y m son coeficiente y exponente, respectivamente.
Uso de la hoja de cálculo, se ajusta a una función de potencia a los siguientes datos:
Verify with ONLINE REGRESSION12.
Verifique con ONLINE REGRESSION12.
ONLINE REGRESSION13 solves the two-predictor-variable
linear regression problem
La calculadora ONLINE REGRESSION13 resuelve el problema de regresión lineal de dos variables-predictivas
Use ONLINE REGRESSION14
to solve the two-predictor-variable nonlinear regression problem of Eq. 7-48, for the data of Problem 7-5.
Utilizar ONLINE REGRESSION14 para resolver el problema de
regresión no lineal de dos variables predictivas de la Ec 7-48, para los datos de Problema 7-5.
The median Qi/Q2.33 ratios (i = frequency) for 10 stations have been found to be 1.95 for the 10-y frequency and 2.45 for the 50-y frequency.
Use the index-flood method to calculate the 25-y flood for a point in a stream having a 340-km2 catchment and a mean annual flood given by the following formula:
La mediana de las relaciones Qi / Q2.33(i = frecuencia)
para 10 estaciones se han encontrado para ser 1.95 para la frecuencia de 10-y y 2.45 para la frecuencia
de 50-y. Utilizar el método de índice de inundación para calcular la
inundación de 25-y para un punto en una corriente que tiene una cuenca de 340-km2
y una inundación anual promedio dada por la siguiente fórmula:
in which Q = flood discharge in cubic meters per second, and A = drainage area in square kilometers.
en la que Q = inundación de descarga en metros cúbicos por segundo, y
A = área de drenaje en kilómetros cuadrados.
Modify the spread sheet developed in Problem 7-2 to calculate the regression constants and correlation coefficient to fit intensity-duration-frequency rainfall data. Test your spread sheet using the data of Example 7-4 in the text.
Modificar la hoja de cálculo desarrollada en el Problema 7-2 para calcular las
constantes de regresión y el coeficiente de correlación para ajustar
los datos de precipitación de intensidad-duración-frecuencia.
Probar su hoja de cálculo utilizando los datos del Ejemplo 7-4 en el texto.
Using ONLINE REGRESSION15 for a hyperbolic regression,
calculate the regression constants a and b (Eq. 7-55) for the following 25-y frequency rainfall data:
Usando la calculadora ONLINE REGRESSION15 para una regresión hiperbólica, calcular las constantes de regresión a and b (Ec. 7-55) para los siguientes datos de
precipitación de 25-y de frecuencia:
BIBLIOGRAFÍA
Benson, M. A. (1962). "Evolution of Methods for Evaluating the Occurrence of Floods," U.S. Geological Survey Water Supply Paper No. 1580-A.
Boughton, W. C., and K. G. Renard. (1984). "Flood Frequency Characteristics of Some Arizona Watersheds," Water Resources Bulletin, Vol. 20, No. 5, October, pp. 761- 769.
Creager, W. P., J. D. Justin, and 1. Hinds. (1945). Engineering for Dams. Vol. 1. New York: John Wiley.
Dalrymple, T. (1960). "Flood Frequency Analyses," U.S. Geological Survey Water Supply Paper No. 1543A.
Hall, M. J. (1984). Urban Hydrology. London: Elsevier Applied Science Publishers.
Malvick, A. J. (1980). "A Magnitude-Frequency-Area Relation for Floods in Arizona," Research Report No. 2, College of Engineering, University of Arizona, Tucson.
McCuen, R. H. (1985). Statistical Methods for Engineers. Englewood Cliffs, N.J.: Prentice-Hall.
Neter, J., W. Wasserman, and M. H. Kutner. (1989). Applied Linear Regression Models, Second Edition, Irwin, Homewood, illinois.
Reich. B. M., H. B. Osborn. and M. C. Baker. (1979). "Tests on Arizona New Flood Estimates," in Hydrology and Water Resources in Arizona and the Southwest, University of Arizona, Tucson, Vol. 9.
Roeske, R. H. (1978). "Methods for Estimating the Magn!tude and Frequency of Floods in Arizona," Final Report, ADOT-RS-lS-121, U.S. Geological Survey, Tucson, Arizona.
U.S. Geological Survey. (1994). "Nationwide Summary of U.S. Geological Survey Regional Regression Equations for Estimating Magnitude and Frequency of Floods for Ungaged Sites, 1993" Compiled by M. E. Jennings, W. O. Thomas, and H. C. Riggs, Water-Resources Investigations Report 94-4002, Reston, Virginia.
Viessman, W. Jr., J. W. Knapp, G. L. Lewis, and T. E. Harbaugh, Introduction to Hydrology, 2d. ed, New York: Harper & Row.
STOP HERE 230927 17:30
-------------------------------------
Tabla 7-1 Regresión de una variable predictiva: Ejemplo 7-2.
(1)
(2)
(3)
(4)
(5)
(6)
(7)
Año
x
(m3/s)y
(m3/s)( x - x̄ )2
( y - ȳ )2
x2
xy
1973
110
89
1,444
144
12,100
9,790
1974
42
51
900
676
1,764
2,142
1975
75
72
9
25
5,625
5,400
1976
120
112
2,304
1,225
14,400
13,440
1977
89
70
289
49
7,921
6,230
1978
32
45
1,600
1,024
1,024
1,440
1979
37
42
1,225
1,225
1,369
1,554
1980
56
59
256
324
3,136
3,304
1981
82
100
100
529
6,724
8,200
1982
90
92
324
225
8,100
8,280
1983
50
70
484
49
2,500
3,500
1984
30
42
1,764
1,225
900
1,260
1985
81
92
81
225
6,561
7,452
1986
110
130
1,444
2,809
12,100
14,300
1987
76
89
16
144
5,776
6,764
Suma
1,080
1,155
12,240
9,898
90,000
93,056
![]()
STOP HERE 230928 10:00
-------------------------------------
y' = α + β1x1 + β2x2
(7-35)
Σ ( y - y' )2 = Σ [ y - (α + β1x1 + β2x2) ] 2
(7-36)
Σ y - nα - β1 Σx1 - β2 Σx2 = 0
(7-37)
Σ yx1 - αΣ x1 - β1 Σ x12 - β2 Σ x1x2 = 0
(7-38)
Σ yx2 - αΣ x2 - β2 Σ x22 - β1 Σ x1x2 = 0
(7-39)
( nΣyx2 - Σy Σx2 )( nΣx1x2 - Σx1 Σx2 ) - [ nΣx22 - (Σx2 )2] [ nΣyx1 - ΣyΣx1]
β1 = ___________________________________________________________________________________
(nΣx1x2 - Σx1Σx2)2 - [nΣx12 - (Σx1)2] [nΣx22 - (Σx2)2]
(7-40)
( nΣyx1 - Σy Σx1 ) - β1 [nΣx12 - (Σx1)2]
β2 = ______________________________________________
nΣx1x2 - Σx1 Σx2
(7-41)
Σy - β1Σx1 - β2Σx2
α = ___________________________
n
(7-42)
1
se = [ _______ Σ (y - y' )2 ] 1/2
n - 3
(7-43)
n - 1
se = sy [ _______ ( 1 - R 2 ) ] 1/2
n - 3
(7-44)
R 2 = 1 - (SSE / SSTO )
(7-45)
SSE = Σ ( y - y' )2
(7-46)
SSTO = Σ ( y - ȳ )2
(7-47)
y = a x1b1 x2b2
(7-48)
log y = log a + b1 log x1 + b2 log x2
(7-49)
y = 10α x1β1 x2β2
(7-50)
STOP HERE 231010 14:00
-------------------------------------
Qp = c A m
(7-51)
Qp = c A nA-m
(7-52)
Qp = c A a - b log A
(7-53)
cA
Qp = ______________ + dA
(a + bA ) m
(7-54)
STOP HERE 231023 10:00
-------------------------------------
STOP HERE 231120 10:00
-------------------------------------
Table 7-2 Index-Flood Method: Example 7-3. / Tabla 7-2 Método de Índice-Inundación: Ejemplo 7-3.
(1)
(2)
(3)
(4)
(5)
(6)
(7)
(8)
Station/ Estación
iQi /Q 2.33 for the j th Return Period (years) /Qi /Q 2.33 para la j th Período de Retorno (años)
1.11
1.25
2
5
10
25
50
1
0.32
0.49
0.90
1.45
1.82
2.28
2.62
2
0.35
0.51
0.92
1.44
1.79
2.23
2.56
3
0.39
0.55
0.92
1.40
1.73
2.14
2.44
4
0.27
0.45
0.90
1.50
1.88
2.38
2.74
5
0.31
0.50
0.91
1.46
1.84
2.32
2.68
Median / Mediana
0.32
0.50
0.91
1.45
1.82
2.28
2.62
Rainfall Intensity-Duration-Frequency
Rainfall duration tr (min) / Duración de precipitación tr (min)
5
10
15
30
60
120
180
Rainfall intensity i (cm/h) / Intensidad de precipitación i (cm/h)
8
5
4
2.5
1.5
1.0
0.8
a
i = ___________
tr + b
(7-55)
******************************************************
1 tr b
___ = ____ + ____
i a a
(7-56)
![]()
State Equations for Regional Flood Frequency
Stream A
(ac-ft) /
Arroyo A
(ac-ft) 1000
2000
3000
4000
5000
Stream B
(ac-ft) / Arroyo B
(ac-ft)
1000
0.07
0.03
0.02
0.00
0.00
2000
0.03
0.08
0.04
0.03
0.00
3000
0.02
0.04
0.08
0.05
0.02
4000
0.00
0.04
0.08
0.11
0.06
5000
0.00
0.00
0.03
0.08
0.09
Stream / (Corriente) X
(m3/s)Stream / Corriente Y
(m3/s)50
65
66
76
32
45
78
95
12
18
34
50
23
31
50
64
43
67
89
99
76
89
22
33
Qp = cAn
Qp = cAn
Peak Discharge / Descarga Máxima
(m3/s)Drainage Area / Área de Descarga
(km2)124
25
254
46
378
78
101
22
678
99
540
89
490
83
267
52
350
73
Y
Time of Concentration / Tiempo de Concentración
(min)X1
Hydraulic Length / Longitud Hidráulica
(m)X2
Catchment Slope / Pendiente de Captación
(m/m)89
3245
0.008
75
2567
0.011
57
2783
0.009
34
1234
0.015
101
5345
0.006
121
5329
0.007
68
3002
0.008
79
2976
0.010
25
1034
0.018
59
2984
0.010
96
3892
0.007
12
534
0.020
Q 2.33 = 3.93 A 0.75
Duration / Duración (min)
5
10
15
30
60
120
180
Intensity / Intensidad (mm/h)
15.5
7.5
6.5
4.5
3.5
2.5
1.5
http://engineeringhydrology.sdsu.edu
230523